BGP Route Reflector Design Options (Part 1): Inter-Cluster Peerings
If we have many iBGP routers within an AS, to solve the scalability issue of the full-mesh requirement we can deploy one (or more) iBGP Route Reflectors. By doing this we create clusters: a cluster consists of one or more Route Reflectors and their clients. In the topology of this lab we're going to have three clusters in the following setup:
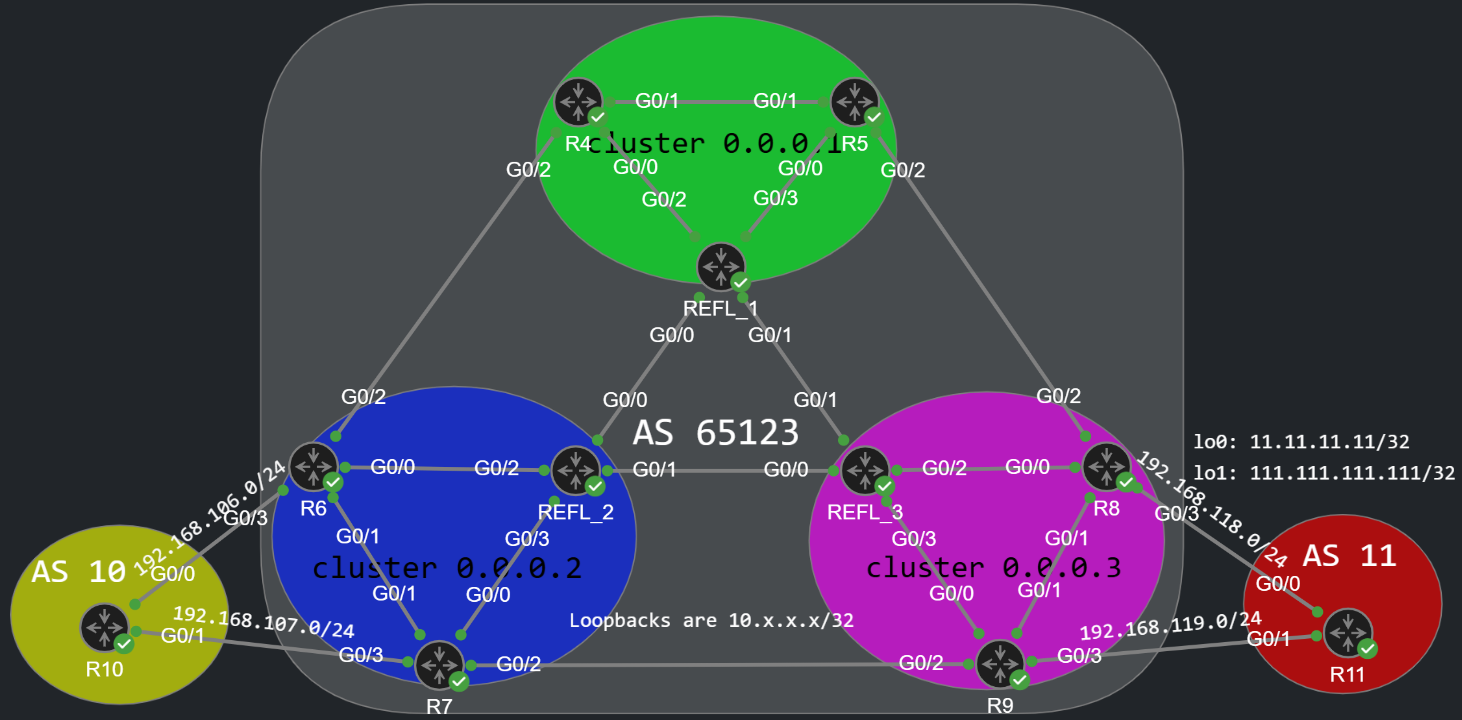
In this topology each cluster is serviced by a single Route Reflector (cluser 0.0.0.1 by REFL_1, cluster 0.0.0.2 by REFL_2 and cluster 0.0.0.3 by REFL_3). Inside each cluster (green, blue and purple areas) every iBGP peer is configured as a client of the Route Reflector. With inter-cluster peerings we have two options: the Route Reflectors can be clients or non-clients of each other. Both design options have some advantages and disadvantages.
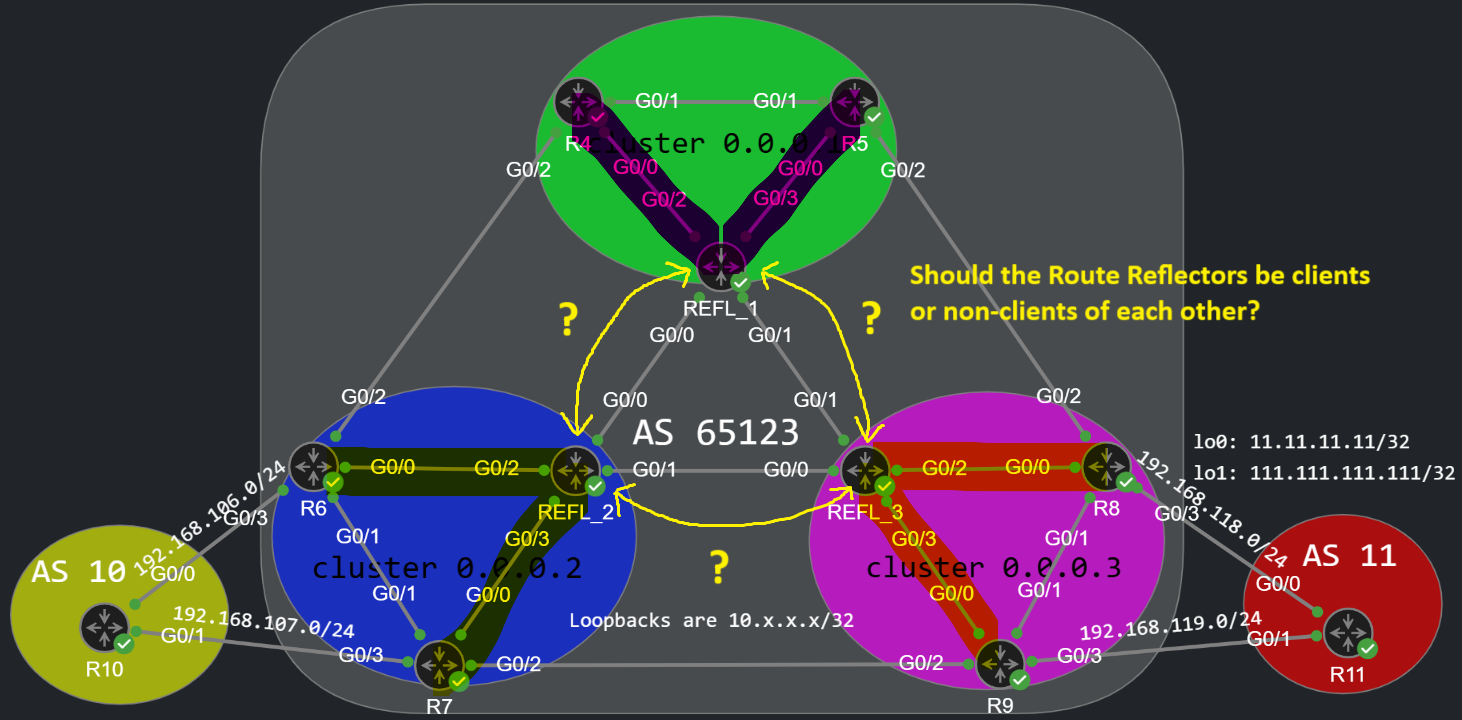
Let's start by configuring the Route Reflectors as non-clients. This is how I configured REFL_1:
REFL_1#show running-config | section bgprouter bgp 65123 bgp cluster-id 0.0.0.1 bgp log-neighbor-changes neighbor 10.2.2.2 remote-as 65123 neighbor 10.2.2.2 update-source Loopback0 neighbor 10.3.3.3 remote-as 65123 neighbor 10.3.3.3 update-source Loopback0 neighbor 10.4.4.4 remote-as 65123 neighbor 10.4.4.4 update-source Loopback0 neighbor 10.5.5.5 remote-as 65123 neighbor 10.5.5.5 update-source Loopback0 ! address-family ipv4 neighbor 10.2.2.2 activate neighbor 10.3.3.3 activate neighbor 10.4.4.4 activate neighbor 10.4.4.4 route-reflector-client neighbor 10.5.5.5 activate neighbor 10.5.5.5 route-reflector-client exit-address-family
First I manually assigned a Cluster-ID, if you don't do this the BGP RID will be the Cluster-ID automatically. R4 and R5 are the clients of REFL_1 while REFL_2 and REFL_3 are non-clients peers. The configuration of the other Route Reflectors are very much the same: both REFL_2 and REFL_3 peer with the other two Reflectors as non-clients. Now we're going to advertise some prefixes from AS 11 and we'll see how the NLRI propagates within AS 65123 and between the clusters. Here are the BGP configurations of R8 and R9 which are the eBGP peers of AS 11:
R8#show run | sec bgprouter bgp 65123 bgp log-neighbor-changes neighbor 10.3.3.3 remote-as 65123 neighbor 10.3.3.3 update-source Loopback0 neighbor 192.168.118.11 remote-as 11 ! address-family ipv4 neighbor 10.3.3.3 activate neighbor 10.3.3.3 next-hop-self neighbor 192.168.118.11 activate exit-address-familyR9#show run | sec bgprouter bgp 65123 bgp log-neighbor-changes neighbor 10.3.3.3 remote-as 65123 neighbor 10.3.3.3 update-source Loopback0 neighbor 192.168.119.11 remote-as 11 ! address-family ipv4 neighbor 10.3.3.3 activate neighbor 10.3.3.3 next-hop-self neighbor 192.168.119.11 activate exit-address-family
They both only peer with their own Route Reflector (REFL_3) in their cluster, and they have next-hop-self configured for the Route Reflector (10.3.3.3): they'll automatically change the next-hop address for every NLRI from AS 11 to their own loopback address. By doing this we don't have to advertise or redistribute the external addresses outside of the AS (192.168.11x.0/24) into the IGP. And now let's advertise the Loopback0 address of R11 with BGP:
R11(config)#router bgp 11R11(config-router)#address-family ipv4 unicastR11(config-router-af)#network 11.11.11.11 mask 255.255.255.255
REFL_3 gets the prefix from both R8 and R9:
REFL_3#show bgp ipv4 unicastBGP table version is 2, local router ID is 10.3.3.3Status codes: s suppressed, d damped, h history, * valid, > best, i - internal, r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter, x best-external, a additional-path, c RIB-compressed, t secondary path, Origin codes: i - IGP, e - EGP, ? - incompleteRPKI validation codes: V valid, I invalid, N Not found Network Next Hop Metric LocPrf Weight Path * i 11.11.11.11/32 10.9.9.9 0 100 0 11 i *>i 10.8.8.8 0 100 0 11 i
REFL_3 chooses his best path through R8. Basically every attribute is equal, the Router-ID of the peer is the tiebreaker here: R8 has lower RID, so R8 is preferred. By default REFL_3 only advertises his best path to his other peers, so the path through 10.9.9.9 won't be advertised to other peers (but that's the issue of another topic). Now let's move to REFL_1 and check his BGP table:
REFL_1#show bgp ipv4 unicast 11.11.11.11/32BGP routing table entry for 11.11.11.11/32, version 20Paths: (1 available, best #1, table default) Advertised to update-groups: 1 Refresh Epoch 1 11 10.8.8.8 (metric 3) from 10.3.3.3 (10.3.3.3) Origin IGP, metric 0, localpref 100, valid, internal, best Originator: 10.8.8.8, Cluster list: 0.0.0.3 rx pathid: 0, tx pathid: 0x0
REFL_1 only got this prefix from REFL_3. REFL_2 does NOT forward this prefix to REFL_1. Why? Because they are non-clients. REFL_3 gets this NLRI from a client (R8), so he forwards it to both clients and non-clients (REFL_1 and REFL_2). REFL_2, from his perspective gets this NLRI from a non-client peer (REFL_3), so he forwards it to only client peers (R6, R7), and he does NOT forward it non-client peers. Now let's take a look at the new path attributes which the Route Reflectors added to this NLRI from R4's point of view:
R4#show ip bgp 11.11.11.11/32BGP routing table entry for 11.11.11.11/32, version 2Paths: (1 available, best #1, table default)Flag: 0x100 Not advertised to any peer Refresh Epoch 2 11 10.8.8.8 (metric 4) from 10.1.1.1 (10.1.1.1) Origin IGP, metric 0, localpref 100, valid, internal, best Originator: 10.8.8.8, Cluster list: 0.0.0.1, 0.0.0.3 rx pathid: 0, tx pathid: 0x0
R4 gets the NLRI from REFL_1. He has two new path attributes: the Originator-ID, and the Cluster-list:
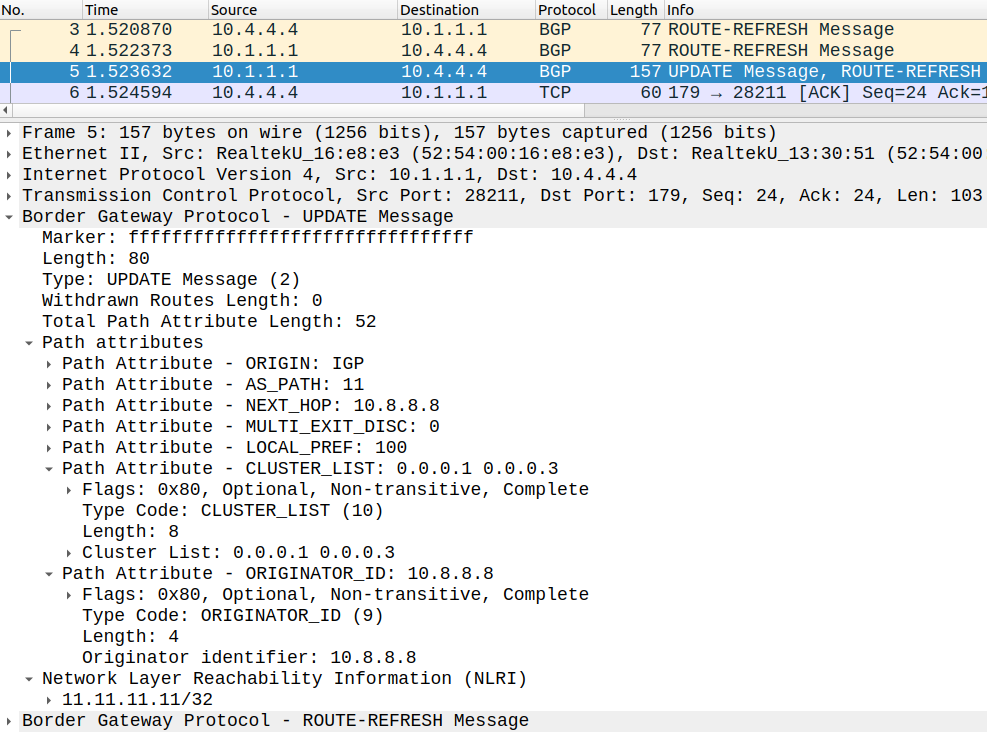
The Originator-ID is added by the first Route Reflector (REFL_3): the Originator-ID is basically the BGP RID of the router who brought this NLRI into the first cluster in the first place (R8 in this case). This doesn't change when the NLRI gets forwarded to other clusters, it stays the same within the whole AS. Besides the Originator-ID the first Route Reflector adds the Cluster-list attribute to this NLRI with his own Cluster-ID. Any other Route Reflector who forwards this NLRI to his clients (or non-clients) prepends his own Cluster-ID to this list. Just like the AS-Path it is used for loop prevention: if a router receives the NLRI with his own Cluster-ID in the Cluster-list, it discards that NLRI. We can see that this NLRI above went though two Route Reflector because the Cluster-list consists of two Cluster-IDs: the Cluster-ID of RELF_3 (0.0.0.3) and the Cluster-ID of REFL_1 (0.0.0.1). It's important that we only should configure the Cluster-ID on the Reflectors within the cluster, we should NOT configure the Cluster-ID on the clients. To demonstrate this let's take a look what happens when I configure the Cluster-ID for R4:
R4(config)#router bgp 65123R4(config-router)#bgp cluster-id 0.0.0.1
And let's do a Route-Refresh while enabling the debugs below:
R4#debug ip bgp updates BGP updates debugging is on for address family: IPv4 Unicast R4#clear ip bgp * inBGP: nbr_topo global 10.1.1.1 IPv4 Unicast:base (0x11200F00:1) rcvd Refresh Start-of-RIBBGP: nbr_topo global 10.1.1.1 IPv4 Unicast:base (0x11200F00:1) refresh_epoch is 6BGP: 10.1.1.1 RR in same cluster. Reflected update droppedBGP(0): 10.1.1.1 rcv UPDATE w/ attr: nexthop 10.8.8.8, origin i, localpref 100, metric 0, originator 10.8.8.8, clusterlist 0.0.0.1 0.0.0.3, merged path 11, AS_PATH , community , extended community , SSA attribute BGPSSA ssacount is 0, Tunnel attribute Tunnel encap type: 0, encap size: 0BGP(0): 10.1.1.1 rcv UPDATE about 11.11.11.11/32 -- DENIED due to: reflected from the same cluster;
The loop prevention mechanism kicks in, and the NLRI gets dropped: DENIED due to: reflected from the same cluster;. So this should be configured only on the Route Reflector. The clients are not aware that they are located in a cluster, moreover they are not aware that they are Route Reflector clients at all. This is only configured on the Reflector itself. So I quickly remove this from R4:
R4(config)#router bgp 65123R4(config-router)#no bgp cluster-id 0.0.0.1
And let's examine what happens if the BGP session breaks between REFL_3 and REFL_1. Notice that the BGP session won't necessarily terminate if the direct link between REFL_1 and REFL_3 breaks: BGP establishes a TCP session, it's not like OSPF which uses link-local multicast. If we use the loopback addresses as source and destinations instead of the physical ones and we have multiple redundant links between the routers the BGP session will be just fine. But what if due to some misconfigurations (for example by using the physical addresses) the BGP session breaks between RELF_1 and REFL3? Let's take a look: I simply shut down the peering:
REFL_1(config-if)#router bgp 65123REFL_1(config-router)#address-family ipv4 unicast REFL_1(config-router-af)#no neighbor 10.3.3.3 activate
That moment every router within the cluster 0.0.0.1 lost the reachability to AS 11:
BGP(0): 10.1.1.1 rcv UPDATE about 11.11.11.11/32 -- withdrawnBGP(0): no valid path for 11.11.11.11/32BGP: topo global:IPv4 Unicast:base Remove_fwdroute for 11.11.11.11/32R4#show ip bgp
Why? Because REFL_2 doesn't forward this NLRI to REFL_1: REFL_1 is a non-client for REFL_2. So if we configure the Reflectors as non-clients of each other, we MUST configure the iBGP peerings of the Reflectors in full-mesh. Now let's look at the other option if we configure the Reflectors as clients of each other like this:
REFL_1(config)#router bgp 65123REFL_1(config-router)#address-family ipv4 unicastREFL_1(config-router-af)#neighbor 10.2.2.2 route-reflector-client %BGP-5-ADJCHANGE: neighbor 10.2.2.2 Down RR client config change%BGP_SESSION-5-ADJCHANGE: neighbor 10.2.2.2 IPv4 Unicast topology base removed from session RR client config change%BGP-5-ADJCHANGE: neighbor 10.2.2.2 Up REFL_1(config-router-af)#neighbor 10.3.3.3 route-reflector-client %BGP-5-ADJCHANGE: neighbor 10.3.3.3 Down RR client config change%BGP_SESSION-5-ADJCHANGE: neighbor 10.3.3.3 IPv4 Unicast topology base removed from session RR client config change%BGP-5-ADJCHANGE: neighbor 10.3.3.3 Up
Notice that the neighbor relationship will break if you change the RR client configuration. So be aware of that, in a production network we should only do things like this in a maintenance window. Here are the configuration of the other two Reflector:
REFL_2(config)#router bgp 65123REFL_2(config-router)#address-family ipv4 unicastREFL_2(config-router-af)#neighbor 10.3.3.3 route-reflector-client REFL_2(config-router-af)#neighbor 10.1.1.1 route-reflector-client REFL_3(config)#router bgp 65123REFL_3(config-router)#address-family ipv4 unicastREFL_3(config-router-af)#neighbor 10.1.1.1 route-reflector-client REFL_3(config-router-af)#neighbor 10.2.2.2 route-reflector-client
And let's advertise a new prefix from AS 11 and let's see how the NLRI propagates between the clusters:
R11(config-if)#router bgp 11R11(config-router)#address-family ipv4 unicast R11(config-router-af)#network 111.111.111.111 mask 255.255.255.255
REFL_1#debug ip bgp updates BGP updates debugging is on for address family: IPv4 Unicast REFL_1#BGP(0): 10.3.3.3 rcvd UPDATE w/ attr: nexthop 10.8.8.8, origin i, localpref 100, metric 0, originator 10.8.8.8, clusterlist 0.0.0.3, merged path 11, AS_PATH BGP(0): 10.3.3.3 rcvd 111.111.111.111/32BGP(0): Revise route installing 1 of 1 routes for 111.111.111.111/32 -> 10.8.8.8(global) to main IP tableBGP(0): (base) 10.2.2.2 send UPDATE (format) 111.111.111.111/32, next 10.8.8.8, metric 0, path 11BGP(0): 10.2.2.2 rcvd UPDATE w/ attr: nexthop 10.8.8.8, origin i, localpref 100, metric 0, originator 10.8.8.8, clusterlist 0.0.0.2 0.0.0.3, merged path 11, AS_PATH BGP(0): 10.2.2.2 rcvd 111.111.111.111/32
Now REFL_1 gets the NLRI from both REFL_2 and REFL_3. Remember that REFL_1 is a client of REFL_2, so this time REFL_2 forwards the NLRI to REFL_1 as well. Let's take a look which path does REFL_1 choose to reach this prefix:
REFL_1#show bgp ipv4 unicast 111.111.111.111/32BGP routing table entry for 111.111.111.111/32, version 13Paths: (2 available, best #2, table default) Advertised to update-groups: 1 Refresh Epoch 2 11, (Received from a RR-client) 10.8.8.8 (metric 3) from 10.2.2.2 (10.2.2.2) Origin IGP, metric 0, localpref 100, valid, internal Originator: 10.8.8.8, Cluster list: 0.0.0.2, 0.0.0.3 rx pathid: 0, tx pathid: 0 Refresh Epoch 2 11, (Received from a RR-client) 10.8.8.8 (metric 3) from 10.3.3.3 (10.3.3.3) Origin IGP, metric 0, localpref 100, valid, internal, best Originator: 10.8.8.8, Cluster list: 0.0.0.3 rx pathid: 0, tx pathid: 0x0
It chose the path through REFL_3 (10.3.3.3). Why? Because it has shorter Cluster-list length. Like AS-Path, shorter Cluster-list length is preferred, but it's really down in the list of the path attributes, it's just before the lowest RID. So you can use basically anything else for path manipulation: Local Preference, AS-Path, MED etc. Here in the example above everything is equal, so the Cluster-list length is used as the tiebreaker (0.0.0.3vs 0.0.0.2 0.0.0.3). So if we configure the Reflectors as clients of each other we have more redundancy. But what's the downside of this setup? We have many redundant Updates between the Reflectors. Now we just have two prefixes and three Reflectors. Imagine that what if we had more? Maybe thousands of prefixes. The lot of Updates could overwhelm the control-plane of the Reflectors and the CPU utilization could suffer. We create a feedback loop: basically every Reflector forwards every NLRI to everywhere. Eventually the feedback loop will break because of the loop prevention of the Cluster-list attribute: so we will receive back every BGP Update we sent out. So this option provides additional redundancy but if we have many Reflectors and many prefixes this could easily cause utilization problems. Let's take a look at one more thing: what happens with these two additional path attributes when the NLRI is sent to AS 10?
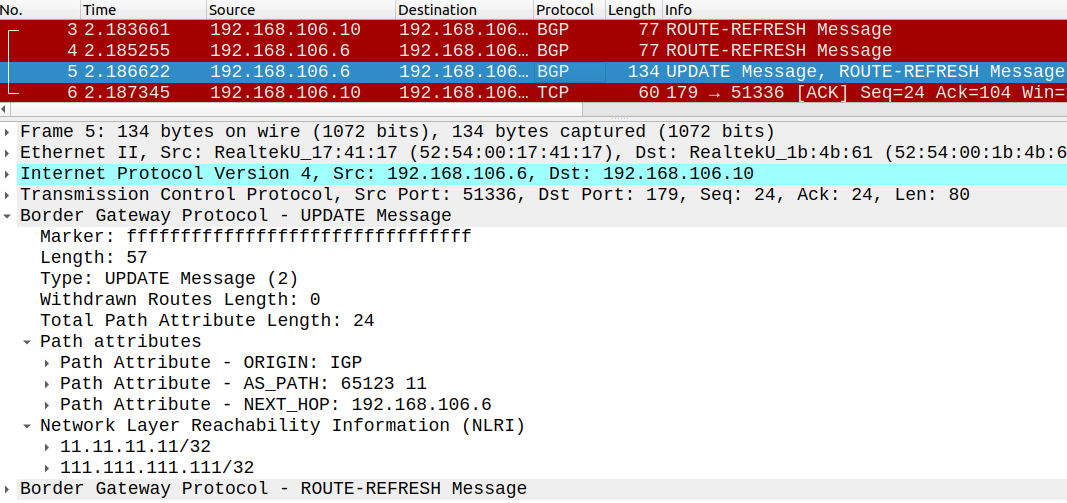
As we can see these are only relevant within the AS, because they are both optional, non-transitive attributes. When R6 sends this NLRI to his eBGP peer, it removes the two additional path attributes which are only relevant in the Route Reflector environment.