Implementing Unified MPLS
Because of scalability reasons we might have multiple IGP processes running within our core network. If we have many routers and prefixes we might have separate IGP "islands" within the core, and we don't want to redistribute the prefixes, because we don't want to increase the number of LSAs in our OSPF LSDB for example. Remember OSPF and ISIS are IGPs, not BGP, they have pretty much an upper limit how many nodes and prefixes they can handle with a single process. Take a look at the following topology:

In a real world environment a single IGP process easily could handle ten nodes of course, but I just wanted to demonstrate the problem: instead breaking OSPF into multiple areas, we have multiple instances of the process, and separate IGP "islands" because of scalability issues. The same problem occurs if two ISPs merge with each other, LDP will be broken between the islands. Or maybe the IGP island in the middle is the core network within the service provider's infrastructure and the two small chucks on the left and right sides are the access network of the infrastructure. Either way we can't use LDP between the islands, so we'll use BGP to transport the label information.
In this example above I have three separate OSPF networks, I use process ID 1 in the core on every router, PID 78 on the left, and PID 910 on the right. The process IDs don't have to be the same on the routers of course, I just wanted to make it consistent to demonstrate which routers have the same LSDB. At this point R5 and R6 are not ASBRs, because I haven't done any redistribution on the routers yet. They are just regular routers which have two separate LSDBs. In order to make the LSP end-to-end between the PE routers we have to configure the following BGP sessions, that I tried to draw in the topology below:
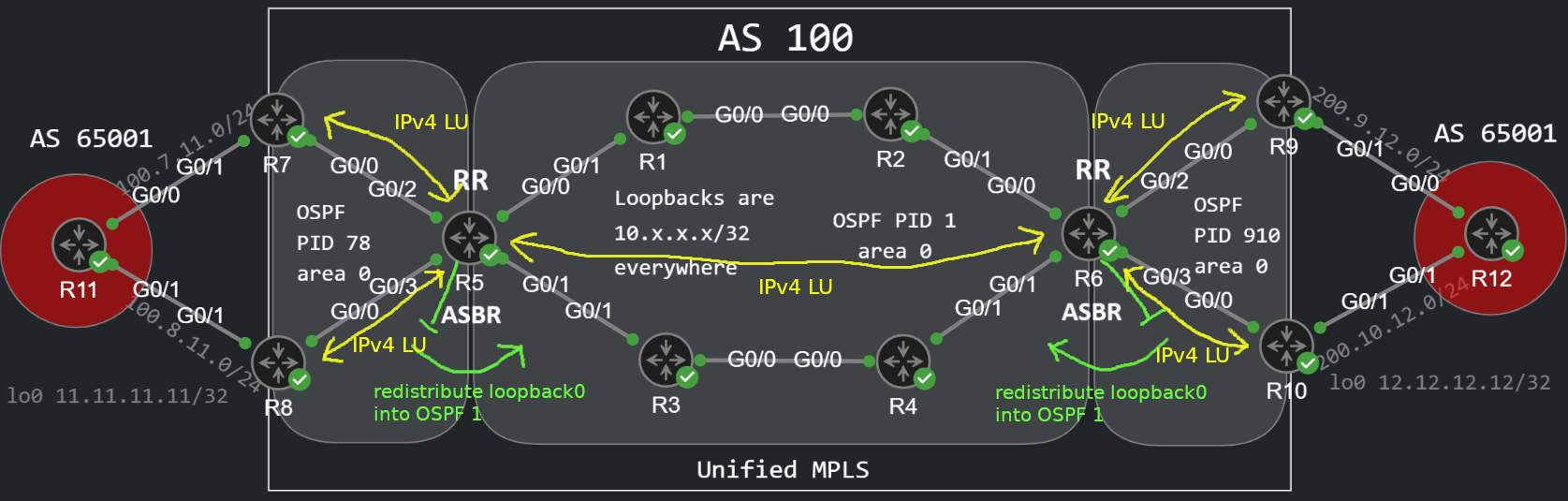
We have to establish the IPv4 Labeled Unicast (IPv4 LU) sessions between the routers above, R5 and R6 must be configured as Route Reflectors (RR) because of the iBGP split-horizon rule (remember all routers are in the same AS!). In this example the loopback of R5 (10.5.5.5/32) is advertised in OSPF 78, and the loopback of R6 (10.6.6.6/32) is advertised in OSPF 910. We need to redistribute those into OSPF 1, so that R5 and R6 can reach each other via their loopback address. Notice that we're only redistributing the loopback address, not the whole LSDB! If we were redistributing the whole LSDB, that would create a lot of Type-5 LSAs and it would simply beat the purpose of the concept of unified MPLS.
Redistributing the loopbacks into OSPF 1
So let's start with this, I use a prefix-list to match the loopback address, and I use a route-map with the redistribute command:
R5(config)#ip prefix-list L0 permit 10.5.5.5/32R5(config)#route-map REDIST permit 10R5(config-route-map)#match ip address prefix-list L0R5(config)#router ospf 1R5(config-router)#redistribute ospf 78 subnets route-map REDIST
And we do the same thing on R6:
R6(config)#ip prefix-list L0 permit 10.6.6.6/32R6(config)#route-map REDIST permit 10R6(config-route-map)#match ip address prefix-list L0R6(config)#router ospf 1R6(config-router)#redistribute ospf 910 subnets route-map REDIST
So if I check the routing table of R1 for example:
R1#show ip route ospf | begin GateGateway of last resort is not set 10.0.0.0/8 is variably subnetted, 14 subnets, 2 masksO 10.0.26.0/24 [110/2] via 10.0.12.2, 01:00:02, GigabitEthernet0/0O 10.0.34.0/24 [110/3] via 10.0.15.5, 00:52:54, GigabitEthernet0/1O 10.0.35.0/24 [110/2] via 10.0.15.5, 00:52:54, GigabitEthernet0/1O 10.0.46.0/24 [110/3] via 10.0.12.2, 00:47:11, GigabitEthernet0/0O 10.2.2.2/32 [110/2] via 10.0.12.2, 01:00:15, GigabitEthernet0/0O 10.3.3.3/32 [110/3] via 10.0.15.5, 00:52:54, GigabitEthernet0/1O 10.4.4.4/32 [110/4] via 10.0.15.5, 00:52:54, GigabitEthernet0/1 [110/4] via 10.0.12.2, 00:47:11, GigabitEthernet0/0O E2 10.5.5.5/32 [110/1] via 10.0.15.5, 00:16:07, GigabitEthernet0/1O E2 10.6.6.6/32 [110/1] via 10.0.12.2, 00:07:01, GigabitEthernet0/0
We can see that we have two external (O E2) prefixes which are the two redistributed loopbacks.
Building the IPv4 LU BGP sessions and advertising the loopbacks
Next we build the IPv4 LU sessions between R7-R5, and R8-R5:
R7(config)#router bgp 100R7(config-router)#no bgp default ipv4-unicast R7(config-router)#neighbor 10.5.5.5 remote-as 100R7(config-router)#neighbor 10.5.5.5 update-source lo0R7(config-router)#address-family ipv4 unicast R7(config-router-af)#neighbor 10.5.5.5 activate R7(config-router-af)#neighbor 10.5.5.5 send-label R7(config-router-af)#network 10.7.7.7 mask 255.255.255.255R8(config)#router bgp 100R8(config-router)#no bgp default ipv4-unicast R8(config-router)#neighbor 10.5.5.5 remote-as 100R8(config-router)#neighbor 10.5.5.5 update-source lo0R8(config-router)#address-family ipv4 unicast R8(config-router-af)#neighbor 10.5.5.5 activate R8(config-router-af)#neighbor 10.5.5.5 send-label R8(config-router-af)#network 10.8.8.8 mask 255.255.255.255
Notice that we also use iBGP to advertise the loopbacks of R7 and R8 with the network command, we can't redistribute those into the IGP on the ASBR. As we've seen in my CSC post for example, we activate the IPv4 LU address family with the send-label command. On R5 we configure these peers as RR-clients, furthermore R6 is also configured as RR-client. So the two ASBRs (R5 and R6) are going to be RR-clients of each other. Here is the BGP configuration of R5:
R5(config-router-af)#do show run | sec bgprouter bgp 100 bgp log-neighbor-changes no bgp default ipv4-unicast neighbor 10.6.6.6 remote-as 100 neighbor 10.6.6.6 update-source Loopback0 neighbor 10.7.7.7 remote-as 100 neighbor 10.7.7.7 update-source Loopback0 neighbor 10.8.8.8 remote-as 100 neighbor 10.8.8.8 update-source Loopback0 ! address-family ipv4 neighbor 10.6.6.6 activate neighbor 10.6.6.6 route-reflector-client neighbor 10.6.6.6 send-label neighbor 10.7.7.7 activate neighbor 10.7.7.7 route-reflector-client neighbor 10.7.7.7 send-label neighbor 10.8.8.8 activate neighbor 10.8.8.8 route-reflector-client neighbor 10.8.8.8 send-label exit-address-family
Now let's configure the left side (R6, R9 and R10). The left side is simply going to be a mirror image of the configuration above. R6 is going to be a RR, and R9 and R10 advertise their loopbacks via iBGP.
R9(config)#router bgp 100R9(config-router)#no bgp default ipv4-unicast R9(config-router)#neighbor 10.6.6.6 remote-as 100R9(config-router)#neighbor 10.6.6.6 update-source lo0R9(config-router)#address-family ipv4 unicast R9(config-router-af)#neighbor 10.6.6.6 activate R9(config-router-af)#neighbor 10.6.6.6 send-label R9(config-router-af)#network 10.9.9.9 mask 255.255.255.255R10(config)#router bgp 100R10(config-router)#no bgp default ipv4-unicast R10(config-router)#neighbor 10.6.6.6 remote-as 100R10(config-router)#neighbor 10.6.6.6 update-source lo0R10(config-router)#address-family ipv4 unicast R10(config-router-af)#neighbor 10.6.6.6 activate R10(config-router-af)#neighbor 10.6.6.6 send-label R10(config-router-af)#network 10.10.10.10 mask 255.255.255.255
And here is the configuration of R6:
router bgp 100 bgp log-neighbor-changes no bgp default ipv4-unicast neighbor 10.5.5.5 remote-as 100 neighbor 10.5.5.5 update-source Loopback0 neighbor 10.9.9.9 remote-as 100 neighbor 10.9.9.9 update-source Loopback0 neighbor 10.10.10.10 remote-as 100 neighbor 10.10.10.10 update-source Loopback0 ! address-family ipv4 neighbor 10.5.5.5 activate neighbor 10.5.5.5 route-reflector-client neighbor 10.5.5.5 send-label neighbor 10.9.9.9 activate neighbor 10.9.9.9 route-reflector-client neighbor 10.9.9.9 send-label neighbor 10.10.10.10 activate neighbor 10.10.10.10 route-reflector-client neighbor 10.10.10.10 send-label exit-address-family
BGP next-hop issues - next-hop-self all
Now you'd think that we're done, but we're not. Let's check the BGP table of R5 for example:
R5#show bgp ipv4 unicast | begin Net Network Next Hop Metric LocPrf Weight Path r>i 10.7.7.7/32 10.7.7.7 0 100 0 i r>i 10.8.8.8/32 10.8.8.8 0 100 0 i * i 10.9.9.9/32 10.9.9.9 0 100 0 i * i 10.10.10.10/32 10.10.10.10 0 100 0 i
We have an 'r' RIB-failure for the prefix 10.7.7.7/32 and 10.8.8.8/32, but that's not the problem. This is because R5 also learned these prefixes via OSPF which has a lower AD. The problem is that R5 cannot reach the next-hop for the prefixes 10.9.9.9/32 and 10.10.10.10/32 (the loopbacks of R9 and R10), this also means that R5 won't forward these prefixes to any of his peers. The situation is similar on the other side, we have exactly the same problem on R6:
R6#show bgp ipv4 unicast | begin Netw Network Next Hop Metric LocPrf Weight Path * i 10.7.7.7/32 10.7.7.7 0 100 0 i * i 10.8.8.8/32 10.8.8.8 0 100 0 i r>i 10.9.9.9/32 10.9.9.9 0 100 0 i r>i 10.10.10.10/32 10.10.10.10 0 100 0 i
Remember that we use iBGP here, routers don't change the next-hop address when sending the NLRI to iBGP peers. So we need the next-hop-self command. But the next-hop-self wouldn't work here, this command is used when the router receives the prefixes from eBGP peers, then it changes the next-hop address to this own address when forwarding the prefix to his iBGP peers. Now R6 receives the prefix from iBGP peers (R9 and R10), and forwards the prefix to another iBGP peer (R5), in this case we have to use the next-hop-self all command, like this:
R5(config-router-af)#neighbor 10.6.6.6 next-hop-self all
Now R5 changes the next-hop address to his own address (10.5.5.5) when he forwards the prefixes to R6. So now R6 should be able to reach R7 and R8 via R5:
R6#show bgp ipv4 unicast | begin Netw Network Next Hop Metric LocPrf Weight Path *>i 10.7.7.7/32 10.5.5.5 0 100 0 i *>i 10.8.8.8/32 10.5.5.5 0 100 0 i r>i 10.9.9.9/32 10.9.9.9 0 100 0 i r>i 10.10.10.10/32 10.10.10.10 0 100 0 i
Now the next-hop has been changed for 10.7.7.7/32 and 10.8.8.8/32 as we can see above. Now let's take a look at the BGP table of R9 for example:
R9#show bgp ipv4 unicast | begin Net Network Next Hop Metric LocPrf Weight Path * i 10.7.7.7/32 10.5.5.5 0 100 0 i * i 10.8.8.8/32 10.5.5.5 0 100 0 i *> 10.9.9.9/32 0.0.0.0 0 32768 i r>i 10.10.10.10/32 10.10.10.10 0 100 0 i
We have the same issue here, R9 still can't reach the loopback of R5, so we have to do the next-hop-self all on R6 as well. Basically we have to configure EVERY iBGP peer with next-hop-self allon the RRs:
R5(config-router-af)#neighbor 10.6.6.6 next-hop-self allR5(config-router-af)#neighbor 10.7.7.7 next-hop-self allR5(config-router-af)#neighbor 10.8.8.8 next-hop-self allR6(config-router-af)#neighbor 10.9.9.9 next-hop-self allR6(config-router-af)#neighbor 10.10.10.10 next-hop-self allR6(config-router-af)#neighbor 10.5.5.5 next-hop-self all
Now R9 should be able to reach R7 and R8 using the loopback address of R6 as the next-hop:
R9#show bgp ipv4 unicast | begin Net Network Next Hop Metric LocPrf Weight Path *>i 10.7.7.7/32 10.6.6.6 0 100 0 i *>i 10.8.8.8/32 10.6.6.6 0 100 0 i *> 10.9.9.9/32 0.0.0.0 0 32768 i r>i 10.10.10.10/32 10.6.6.6 0 100 0 i
Verification
Now we should have an end-to-end LSP between the PE routers. Let's verify with a traceroute:
R7#traceroute 10.9.9.9 source lo0 numType escape sequence to abort.Tracing the route to 10.9.9.9VRF info: (vrf in name/id, vrf out name/id) 1 10.0.57.5 [MPLS: Label 5011 Exp 0] 5 msec 4 msec 4 msec 2 10.0.35.3 [MPLS: Labels 3008/6008 Exp 0] 4 msec 5 msec 4 msec 3 10.0.34.4 [MPLS: Labels 4008/6008 Exp 0] 5 msec 4 msec 4 msec 4 10.0.46.6 [MPLS: Label 6008 Exp 0] 4 msec 4 msec 4 msec 5 10.0.69.9 4 msec * 5 msec
R7 can reach the remote PE (R9). R7 uses the transport label 5011 which he received via iBGP:
R7#show ip bgp 10.9.9.9/32BGP routing table entry for 10.9.9.9/32, version 8Paths: (1 available, best #1, table default) Not advertised to any peer Refresh Epoch 4 Local 10.5.5.5 (metric 2) from 10.5.5.5 (10.5.5.5) Origin IGP, metric 0, localpref 100, valid, internal, best Originator: 10.9.9.9, Cluster list: 10.5.5.5, 10.6.6.6 mpls labels in/out nolabel/5011 rx pathid: 0, tx pathid: 0x0
Notice that these labels are not provided by LDP, BGP LU Updates carry the label information:
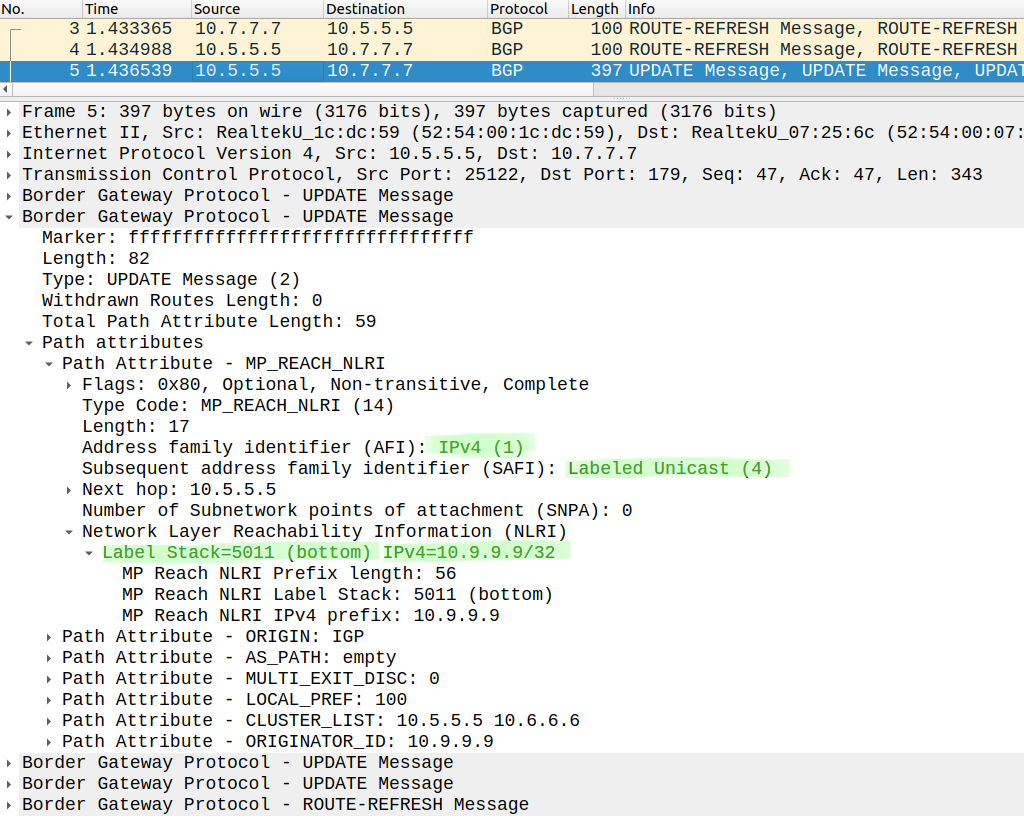
This is the BGP Update R5 sent to R9: the LU Update contains both the prefix (10.9.9.9/32) and a corresponding label (5011). Notice that this NLRI has already been reflected by two RRs (10.5.5.5 and 10.6.6.6) we can determine this based on the Cluster-list attribute. We can also see that R9 advertised this prefix with the network command, because the Originator ID is 10.9.9.9 (R9).
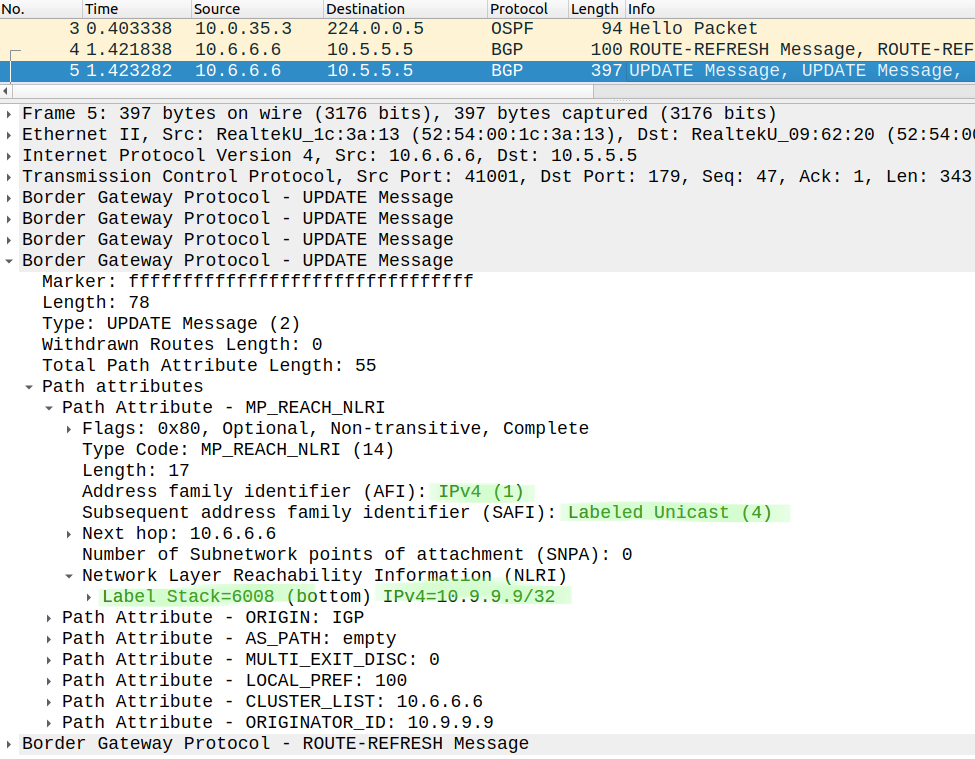
When R5 receives the packet with the label 5011, he swaps it with the label 6008:
R5#show ip bgp 10.9.9.9/32BGP routing table entry for 10.9.9.9/32, version 7Paths: (1 available, best #1, table default) Advertised to update-groups: 3 Refresh Epoch 4 Local, (Received from a RR-client) 10.6.6.6 (metric 1) from 10.6.6.6 (10.6.6.6) Origin IGP, metric 0, localpref 100, valid, internal, best Originator: 10.9.9.9, Cluster list: 10.6.6.6 mpls labels in/out 5011/6008 rx pathid: 0, tx pathid: 0x0
which he got from R6 via iBGP LU:
Also R5 inserts a new transport label (3008) when he forwards the packet to R3:
R5#show ip cef 10.9.9.910.9.9.9/32 nexthop 10.0.15.1 GigabitEthernet0/0 label 1008-(local:5010) 6008 nexthop 10.0.35.3 GigabitEthernet0/1 label 3008-(local:5010) 6008
This transport label will only be used within the core IGP island in the middle, R3 swaps it to 4008, and R4 pops the label (PHP). Finally R6 forwards the packet to R9 based on the label 6008.
Now we can set up an L3VPN service for the red customer (AS 65001). Basically at this point we can have any kind of configuration: we can use Route Reflectors if we want, or we can just simply configure the four PEs in a full mesh, we can do whatever we want, we don't have any restrictions at this point. The configuration of the VPNv4 sessions is the same just like in any other intra-AS L3VPN environment.
In this example I configured the VPNv4 sessions between the same routers as I did the IPv4 LU sessions. The IPv4 LU sessions were already up, so I just activated the VPNv4 address families everywhere. So we have two Route Reflectors R5 and R6, nevertheless this is probably not the most optimal design for this topology. We use BGP as the PE-CE routing protocol and R11 and R12 advertise their loopback address, this is the BGP table of R11:
R11#show ip bgp | beg Net Network Next Hop Metric LocPrf Weight Path *> 11.11.11.11/32 0.0.0.0 0 32768 i * 12.12.12.12/32 100.8.11.8 0 100 100 i *> 100.7.11.7 0 100 100 i
Notice that we use as-override on the PE routers in this topology, I wrote about the as-override and other AS-PATH manipulation techniques in this post.
Now if we run a traceroute on R11 we'll have an additional VPN label, so there will be three MPLS labels in the core IGP island in total:
R11#traceroute 12.12.12.12 so lo0 numType escape sequence to abort.Tracing the route to 12.12.12.12VRF info: (vrf in name/id, vrf out name/id) 1 100.7.11.7 1 msec 1 msec 1 msec 2 10.0.57.5 [MPLS: Labels 5011/9003 Exp 0] 5 msec 5 msec 5 msec 3 10.0.35.3 [MPLS: Labels 3008/6008/9003 Exp 0] 6 msec 5 msec 4 msec 4 10.0.34.4 [MPLS: Labels 4008/6008/9003 Exp 0] 5 msec 7 msec 5 msec 5 10.0.46.6 [MPLS: Labels 6008/9003 Exp 0] 6 msec 6 msec 5 msec 6 200.9.12.9 [MPLS: Label 9003 Exp 0] 5 msec 5 msec 5 msec 7 200.9.12.12 5 msec * 5 msec
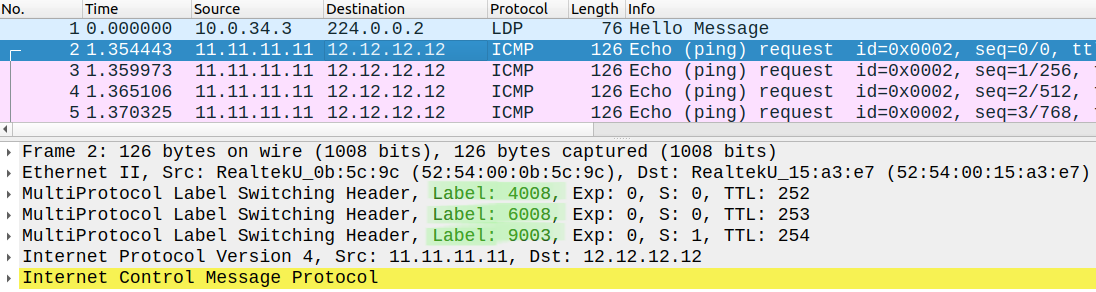
Just like with other intra-AS L3VPN services, the VPN label (9003) remains the same throughout the path, this identifies the remote PE, so we use R9 to reach the loopback of R12 in this case.